Test Session
Overview
After running your test suite against a Build in your CI system, you record your test results in Launchable using the CLI. Those results are recorded against a test session.
Therefore, a test session is a record of:
A certain list of tests that ran
How long each test took to run
Each test's pass/fail/skipped status
Aggregate statistics about the above (e.g., total duration, total count, and total passed/failed/skipped counts)

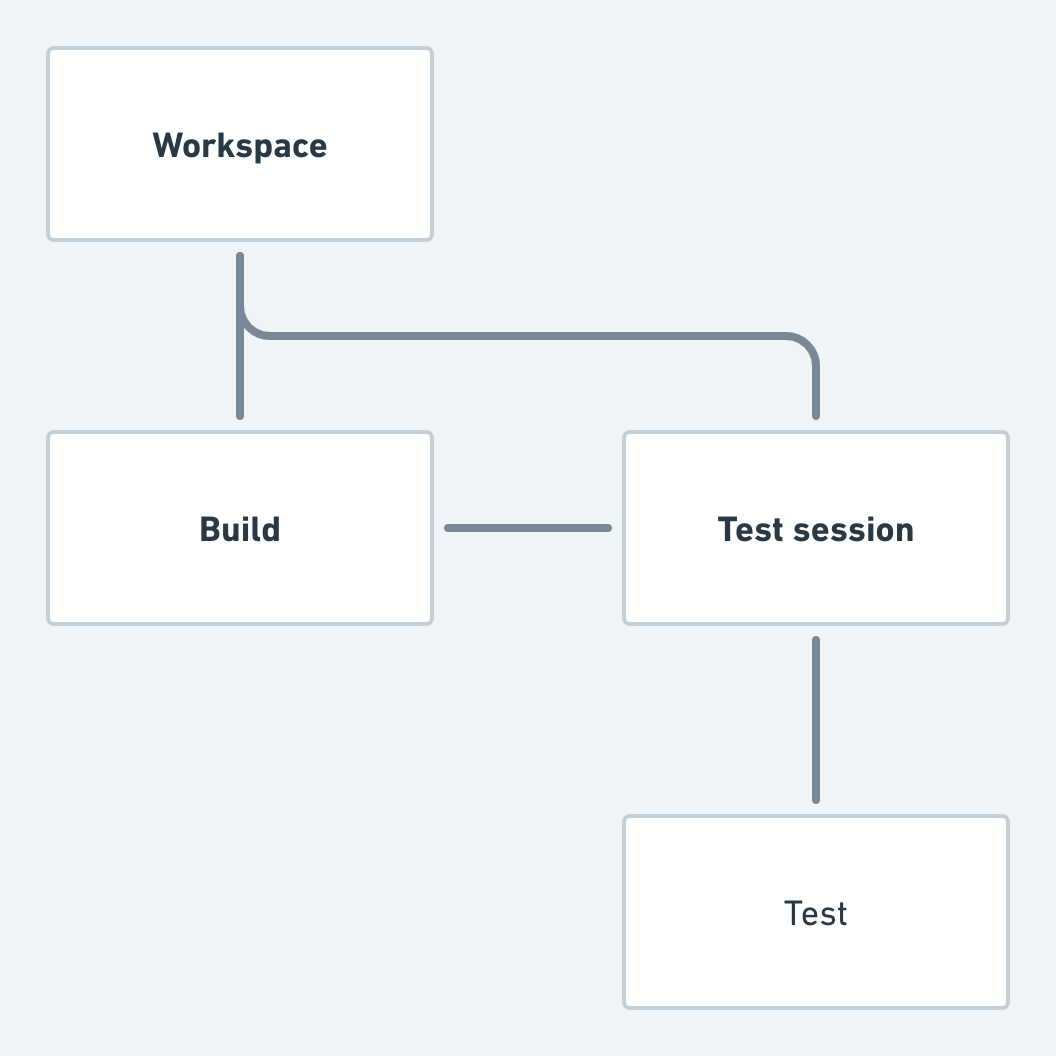
Test sessions across Launchable
Test sessions are a key Launchable concept and, as such, are used for lots of purposes.
Test results and reports
Test results and reports are organized by test sessions. The test session details page shows test counts, total duration, and failed tests per test session.
Insights
Some Insights, particularly Trends, are aggregated by test session. For example, the Test session duration and Test session frequency insights show data aggregated across test sessions in a workspace.
Predictive Test Selection
Test sessions are used for evaluating Predictive Test Selection models. For example, the Confidence curve is built by running existing test sessions through the model to see how long it would have taken for a model to find a failing test in a failing run. Therefore, the length of the X-axis of the Confidence curve corresponds with the length of your longest recent test session.
Test session layouts
Different teams organize their tests in different ways, called "layouts."
Your team's layout impacts how you should record tests in a workspace. This section outlines a few common layouts, including guidance on when you might want to split your runs into multiple test sessions against a single build.
See #Test suites and workspaces for guidance on splitting tests between workspaces.
Default layout
In many cases, builds and test sessions map 1:1. For example, a developer pushes a change, the change is built, and the build is tested. The test runner (e.g., pytest) is run once with a single list of tests.
The CLI handles this default case without any extra steps. Just run launchable record tests at the end of your run to capture test results in a single session.

Running tests in different environments
Some teams run their tests across several environments. For example, UI tests might be run in different browsers. In this case, your build will have multiple test sessions per build: one per environment.


Test sessions have an optional attribute called flavor that handles this. To implement this test session layout, see Using 'flavors' to run the best tests for an environment.
Running tests in parallel
Parallelization is a highly effective strategy for reducing test feedback delay. Depending on how you parallelize your tests and how you want to analyze them in Launchable, you may want to create multiple test sessions per build.
Automatically generated parallel bins
Some test runners support automatic test parallelization. In this scenario, the test runner typically lets you define how many workers to distribute tests via a configuration option. You kick off tests once, and then the test runner automatically distributes tests into bins for each worker. At the end of the run, test reports are often recorded in a single location on the same machine where tests were kicked off.
This scenario does not warrant separate test sessions for each worker. Since the parallelization process is automatic and opaque, the instrumentation is the same as the default layout described above.


The main difference to note is that the test session duration shown in Launchable will be higher than the "wall clock time" perceived by developers since test reports include machine time and don't know about parallelization. Divide the test session duration by your parallelization factor to get the wall clock time.
If your test runner are automatically distributes tests to parallel workers but does not deposit test result files to a location on the original machine, you'll need to manually create a test session before you run tests. See #combining-test-reports-from-multiple-runs.
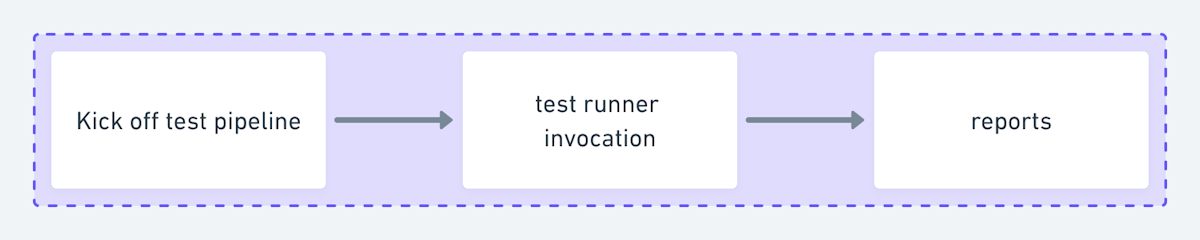
Static bins
Some teams parallelize their tests by manually splitting them into static lists of tests (otherwise known as bins). They might organize tests by functional area (for easier triage), typical duration (to create bins of roughly equal length), or something else.
In this scenario, the test runner is individually invoked once per bin, like this:

This gives you two options for aggregating reports into test sessions:
One session per bin (purple boxes). This option is preferred if:
You have fewer than ~10 bins and/or
You plan to use Predictive Test Selection because a 1:1:1 relationship between test runner invocations, test sessions, and subset requests is preferred for the best performance.
One session per pipeline (orange box). This option is preferred if:
You have more than ~10 bins. At this scale, it becomes less useful to analyze tests at the bin level and more useful to analyze them at the pipeline level.
Ultimately, you are the expert on your test suite layout, so you can aggregate at the hierarchy level that makes sense to you. Depending on your choice, you may need to see #Managing test sessions explicitly.
Managing test sessions explicitly
In most cases, the CLI will manage test sessions on your behalf. The launchable record tests command and launchable subset command will automatically create a test session where needed.
However, if your build, test, and/or test report collection processes occur across several machines/processes, you'll probably need to manage test sessions explicitly. This requires explicitly creating a test session using launchable record session and then passing the session value through your pipeline for use in launchable subset and launchable record tests.
The page Managing complex test session layouts describes how to do this.